ארכי טק טורת יחיד ת עיבוד מרכזי ת
|
|
|
- Piers Wheeler
- 5 years ago
- Views:
Transcription
1 ארכי טק טורת יחיד ת עיבוד מרכזי ת ( ) תשס"ג סמסטר א' March, 2007 Hugo Guterman Web site: Arch. CPU L5 Pipeline II 1 Outline More pipelining Control Hazards Registers and Memory Branch Prediction Exceptions and interrupts Examples Arch. CPU L5 Pipeline II 2

2 Taxonomy of Hazards Arch. CPU L5 Pipeline II 3 Control Hazards - Branches Arch. CPU L5 Pipeline II 4


3 Basic Pipeline Arch. CPU L5 Pipeline II 5 Branch Hazards Arch. CPU L5 Pipeline II 6


4 Branch Hazards Arch. CPU L5 Pipeline II 7 Solution assume branch not taken!! Arch. CPU L5 Pipeline II 8


5 What to do if branch taken? Arch. CPU L5 Pipeline II 9 What happens when branch is taken? Arch. CPU L5 Pipeline II 10
6 Side effects Arch. CPU L5 Pipeline II 11 Side effects Arch. CPU L5 Pipeline II 12


7 Move the branch computation forward Arch. CPU L5 Pipeline II 13 Move the branch computation further forward Arch. CPU L5 Pipeline II 14

8 Result: new improved MIPS Datapath Arch. CPU L5 Pipeline II 15 Pipeline Idiosyncrasies Arch. CPU L5 Pipeline II 16

9 Rewrite the code for delay slot Arch. CPU L5 Pipeline II 17 Problems with delay slot Arch. CPU L5 Pipeline II 18

10 Datapath with branch logic Arch. CPU L5 Pipeline II 19 Problems with delay slot Arch. CPU L5 Pipeline II 20
11 Branch prediction is better? Arch. CPU L5 Pipeline II 21 Prediction of non-taken Arch. CPU L5 Pipeline II 22

12 Branch miss-prediction Arch. CPU L5 Pipeline II 23 How to improve?? Arch. CPU L5 Pipeline II 24
13 Arch. CPU L5 Pipeline II 25 Dynamic Branch Prediction Arch. CPU L5 Pipeline II 26

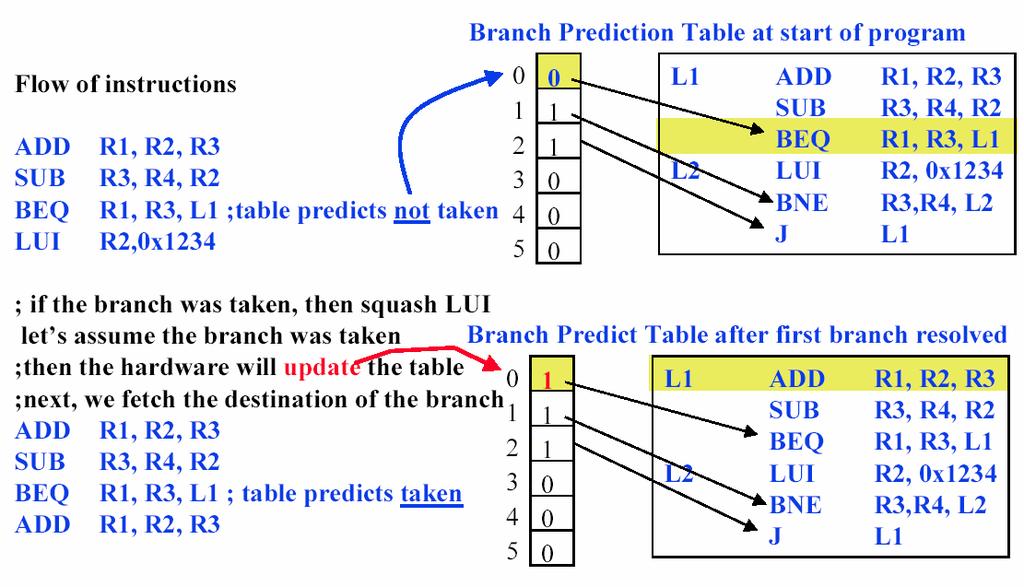
14 1-bit Branch Prediction Arch. CPU L5 Pipeline II 27 1-bit Branch Prediction Arch. CPU L5 Pipeline II 28
15 Dynamic Branch Prediction Solution: 2-bit scheme where change prediction only if get misprediction twice Predict Taken Predict Not Taken T T NT NT T T Predict Taken NT Predict Not Taken NT Arch. CPU L5 Pipeline II 29 Need Same Time as Prediction Branch Target Buffer (BTB): Address of branch index to get prediction AND branch address (if taken) Note: must check for branch match now, since can t use wrong branch address Predicted PC Branch Prediction: Taken or not Taken Return instruction addresses predicted with stack Arch. CPU L5 Pipeline II 30
16 What makes pipelines hard to implement Arch. CPU L5 Pipeline II 31 Exception & Interrupts Arch. CPU L5 Pipeline II 32
17 Exception Flow Arch. CPU L5 Pipeline II 33 Flow of instructions during exception Arch. CPU L5 Pipeline II 34
18 Characterization of exceptions and interrupts Arch. CPU L5 Pipeline II 35 Type of exceptions Arch. CPU L5 Pipeline II 36
19 Stooping and Restarting Execution Arch. CPU L5 Pipeline II 37 Precise vs. Imprecise Exceptions Arch. CPU L5 Pipeline II 38
20 Precise vs. Imprecise Exceptions Arch. CPU L5 Pipeline II 39 Exceptions and CPU Architecture Arch. CPU L5 Pipeline II 40
21 Multiple Exceptions Arch. CPU L5 Pipeline II 41 Multiple Exceptions Arch. CPU L5 Pipeline II 42
22 Exceptions Arch. CPU L5 Pipeline II 43 Performance of Pipelined Systems Arch. CPU L5 Pipeline II 44
23 Data dependencies Arch. CPU L5 Pipeline II 45 Data dependencies Arch. CPU L5 Pipeline II 46
24 Branch delay slot Arch. CPU L5 Pipeline II 47 Branch delay slot Arch. CPU L5 Pipeline II 48
25 Bypass Paths Arch. CPU L5 Pipeline II 49 Bypass Paths Arch. CPU L5 Pipeline II 50
26 Loop unrolling Arch. CPU L5 Pipeline II 51 Loop unrolling Arch. CPU L5 Pipeline II 52
27 Loop unrolling Arch. CPU L5 Pipeline II 53 Code Performance Arch. CPU L5 Pipeline II 54
28 Code Performance Arch. CPU L5 Pipeline II 55 Machine Performance Arch. CPU L5 Pipeline II 56
")
29 Machine Performance Arch. CPU L5 Pipeline II 57 Machine Performance (2) Arch. CPU L5 Pipeline II 58
30 Machine Performance (2) Arch. CPU L5 Pipeline II 59 Pipeline Hazards Again I-Fet ch ID MemOpFetch OpFetch Exec Store Structural Hazard IFetch ID I-Fet ch ID OpFetch Jump Control Hazard IFetch I D IF ID EX Mem WB IF ID EX Mem WB IF ID EX Mem WB RAW (read after write) Data Hazard WAW Data Hazard (write after write) IF ID OF Ex Mem IF ID OF Ex RS WAR Data Hazard (write after read) Arch. CPU L5 Pipeline II 60
31 Data Hazards Avoid some by design eliminate WAR by always fetching operands early (DCD) in pipe eleminate WAW by doing all WBs in order (last stage, static) Detect and resolve remaining ones stall or forward (if possible) IF ID EX Mem WB RAW Data Hazard IF ID EX Mem WB IF ID EX Mem WB WAW Data Hazard IF ID OF Ex Mem IF ID OF Ex RS RAW Data Hazard Arch. CPU L5 Pipeline II 61 Hazard Detection Suppose instruction i is about to be issued and a predecessor instruction j is in the instruction pipeline. A RAW hazard exists on register ρ if ρ Rregs( i ) Wregs( j ) Keep a record of pending writes (for inst's in the pipe) and compare with operand regs of current instruction. When instruction issues, reserve its result register. When on operation completes, remove its write reservation. A WAW hazard exists on register ρ if ρ Wregs( i ) Wregs( j ) A WAR hazard exists on register ρ if ρ Wregs( i ) Rregs( j ) Arch. CPU L5 Pipeline II 62
32 Issues in Pipelined design Pipelining Super-pipeline - Issue one instruction per (fast) cycle - ALU takes multiple cycles IF D Ex M W IF D Ex M W IF D Ex M W IF D Ex M W IF D Ex M W IF D Ex M W IF D Ex M W IF D Ex M W Limitation Issue rate, FU stalls, FU depth Clock skew, FU stalls, FU depth Super-scalar - Issue multiple scalar instructions per cycle IF D Ex M W IF D Ex M W IF D Ex M W IF D Ex M W Hazard resolution VLIW ( EPIC ) - Each instruction specifies multiple scalar operations - Compiler determines parallelism IF D Ex M W Ex M W Ex M W Ex M W Packing Vector operations - Each instruction specifies series of identical operations IF D Ex M W Ex M W Ex M W Ex M W Applicability Arch. CPU L5 Pipeline II 63 Partitioned Instruction Issue (simple Superscalar) independent int and FP issue to separate pipelines I-Cache Int Reg Inst Issue and Bypass FP Reg Operand / Result Busses Int Unit Load / Store Unit FP Add FP Mul D-Cache Single Issue Total Time = Int Time + FP Time Max Speedup: Total Time MAX(Int Time, FP Time) Arch. CPU L5 Pipeline II 64
33 The Big Picture: Where are We Now? The Five Classic Components of a Computer Processor Input Control Memory Datapath Output Arch. CPU L5 Pipeline II 65 FYI: MIPS R3000 clocking discipline phi1 phi2 2-phase non-overlapping clocks Pipeline stage is two (level sensitive) latches Edge-triggered phi1 phi2 phi1 Arch. CPU L5 Pipeline II 66
( ) תשס"ח סמסטר ב' May, 2008 Hugo Guterman Web site:
 תשסח סמסטר ב' May, 2008 Hugo Guterman Web site:") ארכיטקטורת יחידת עיבוד מרכזית (36113741) תשס"ח סמסטר ב' May, 2008 Hugo Guterman (hugo@ee.bgu.ac.il) Web site: http://www.ee.bgu.ac.il/~cpuarch Arch. CPU L5 Pipeline II 1 Outline More pipelining Control
ארכיטקטורת יחידת עיבוד מרכזית (36113741) תשס"ח סמסטר ב' May, 2008 Hugo Guterman (hugo@ee.bgu.ac.il) Web site: http://www.ee.bgu.ac.il/~cpuarch Arch. CPU L5 Pipeline II 1 Outline More pipelining Control
MIPS Pipelining. Computer Organization Architectures for Embedded Computing. Wednesday 8 October 14
 MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
Instruction Level Parallelism. Appendix C and Chapter 3, HP5e
 Instruction Level Parallelism Appendix C and Chapter 3, HP5e Outline Pipelining, Hazards Branch prediction Static and Dynamic Scheduling Speculation Compiler techniques, VLIW Limits of ILP. Implementation
Instruction Level Parallelism Appendix C and Chapter 3, HP5e Outline Pipelining, Hazards Branch prediction Static and Dynamic Scheduling Speculation Compiler techniques, VLIW Limits of ILP. Implementation
Static, multiple-issue (superscaler) pipelines
 pipelines") Static, multiple-issue (superscaler) pipelines Start more than one instruction in the same cycle Instruction Register file EX + MEM + WB PC Instruction Register file EX + MEM + WB 79 A static two-issue
Static, multiple-issue (superscaler) pipelines Start more than one instruction in the same cycle Instruction Register file EX + MEM + WB PC Instruction Register file EX + MEM + WB 79 A static two-issue
3/12/2014. Single Cycle (Review) CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?
 CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?") CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
T a s k B C D. O r d e r
 an Jose tate University EE176 - Fall 1998 Computer rchitecture and Engineering Lecture 12: Introduction to Pipelining (Part II) Instructor: Christopher H. Pham http://www.engr.sjsu.edu/~cpham/ T a s k
an Jose tate University EE176 - Fall 1998 Computer rchitecture and Engineering Lecture 12: Introduction to Pipelining (Part II) Instructor: Christopher H. Pham http://www.engr.sjsu.edu/~cpham/ T a s k
ECE154A Introduction to Computer Architecture. Homework 4 solution
 ECE154A Introduction to Computer Architecture Homework 4 solution 4.16.1 According to Figure 4.65 on the textbook, each register located between two pipeline stages keeps data shown below. Register IF/ID
ECE154A Introduction to Computer Architecture Homework 4 solution 4.16.1 According to Figure 4.65 on the textbook, each register located between two pipeline stages keeps data shown below. Register IF/ID
HY425 Lecture 05: Branch Prediction
 HY425 Lecture 05: Branch Prediction Dimitrios S. Nikolopoulos University of Crete and FORTH-ICS October 19, 2011 Dimitrios S. Nikolopoulos HY425 Lecture 05: Branch Prediction 1 / 45 Exploiting ILP in hardware
HY425 Lecture 05: Branch Prediction Dimitrios S. Nikolopoulos University of Crete and FORTH-ICS October 19, 2011 Dimitrios S. Nikolopoulos HY425 Lecture 05: Branch Prediction 1 / 45 Exploiting ILP in hardware
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
Pipeline Hazards. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Pipeline Hazards Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Hazards What are hazards? Situations that prevent starting the next instruction
Pipeline Hazards Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Hazards What are hazards? Situations that prevent starting the next instruction
Instruction Pipelining
 Instruction Pipelining Simplest form is a 3-stage linear pipeline New instruction fetched each clock cycle Instruction finished each clock cycle Maximal speedup = 3 achieved if and only if all pipe stages
Instruction Pipelining Simplest form is a 3-stage linear pipeline New instruction fetched each clock cycle Instruction finished each clock cycle Maximal speedup = 3 achieved if and only if all pipe stages
Instruction Pipelining
 Instruction Pipelining Simplest form is a 3-stage linear pipeline New instruction fetched each clock cycle Instruction finished each clock cycle Maximal speedup = 3 achieved if and only if all pipe stages
Instruction Pipelining Simplest form is a 3-stage linear pipeline New instruction fetched each clock cycle Instruction finished each clock cycle Maximal speedup = 3 achieved if and only if all pipe stages
NOW Handout Page 1. Review from Last Time #1. CSE 820 Graduate Computer Architecture. Lec 8 Instruction Level Parallelism. Outline
 CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
Computer Architecture 计算机体系结构. Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II. Chao Li, PhD. 李超博士
 Computer Architecture 计算机体系结构 Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2018 Review Hazards (data/name/control) RAW, WAR, WAW hazards Different types
Computer Architecture 计算机体系结构 Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2018 Review Hazards (data/name/control) RAW, WAR, WAW hazards Different types
CSE 820 Graduate Computer Architecture. week 6 Instruction Level Parallelism. Review from Last Time #1
 CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
Multi-cycle Instructions in the Pipeline (Floating Point)
") Lecture 6 Multi-cycle Instructions in the Pipeline (Floating Point) Introduction to instruction level parallelism Recap: Support of multi-cycle instructions in a pipeline (App A.5) Recap: Superpipelining
Lecture 6 Multi-cycle Instructions in the Pipeline (Floating Point) Introduction to instruction level parallelism Recap: Support of multi-cycle instructions in a pipeline (App A.5) Recap: Superpipelining
The Processor Pipeline. Chapter 4, Patterson and Hennessy, 4ed. Section 5.3, 5.4: J P Hayes.
 The Processor Pipeline Chapter 4, Patterson and Hennessy, 4ed. Section 5.3, 5.4: J P Hayes. Pipeline A Basic MIPS Implementation Memory-reference instructions Load Word (lw) and Store Word (sw) ALU instructions
The Processor Pipeline Chapter 4, Patterson and Hennessy, 4ed. Section 5.3, 5.4: J P Hayes. Pipeline A Basic MIPS Implementation Memory-reference instructions Load Word (lw) and Store Word (sw) ALU instructions
LECTURE 3: THE PROCESSOR
 LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
Instruction-Level Parallelism and Its Exploitation
 Chapter 2 Instruction-Level Parallelism and Its Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques es Scoreboarding Tomasulo s s Algorithm Reducing Branch Cost with Dynamic
Chapter 2 Instruction-Level Parallelism and Its Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques es Scoreboarding Tomasulo s s Algorithm Reducing Branch Cost with Dynamic
DEE 1053 Computer Organization Lecture 6: Pipelining
 Dept. Electronics Engineering, National Chiao Tung University DEE 1053 Computer Organization Lecture 6: Pipelining Dr. Tian-Sheuan Chang tschang@twins.ee.nctu.edu.tw Dept. Electronics Engineering National
Dept. Electronics Engineering, National Chiao Tung University DEE 1053 Computer Organization Lecture 6: Pipelining Dr. Tian-Sheuan Chang tschang@twins.ee.nctu.edu.tw Dept. Electronics Engineering National
ECE 505 Computer Architecture
 ECE 505 Computer Architecture Pipelining 2 Berk Sunar and Thomas Eisenbarth Review 5 stages of RISC IF ID EX MEM WB Ideal speedup of pipelining = Pipeline depth (N) Practically Implementation problems
ECE 505 Computer Architecture Pipelining 2 Berk Sunar and Thomas Eisenbarth Review 5 stages of RISC IF ID EX MEM WB Ideal speedup of pipelining = Pipeline depth (N) Practically Implementation problems
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
COSC4201 Instruction Level Parallelism Dynamic Scheduling
 COSC4201 Instruction Level Parallelism Dynamic Scheduling Prof. Mokhtar Aboelaze Parts of these slides are taken from Notes by Prof. David Patterson (UCB) Outline Data dependence and hazards Exposing parallelism
COSC4201 Instruction Level Parallelism Dynamic Scheduling Prof. Mokhtar Aboelaze Parts of these slides are taken from Notes by Prof. David Patterson (UCB) Outline Data dependence and hazards Exposing parallelism
Metodologie di Progettazione Hardware-Software
 Metodologie di Progettazione Hardware-Software Advanced Pipelining and Instruction-Level Paralelism Metodologie di Progettazione Hardware/Software LS Ing. Informatica 1 ILP Instruction-level Parallelism
Metodologie di Progettazione Hardware-Software Advanced Pipelining and Instruction-Level Paralelism Metodologie di Progettazione Hardware/Software LS Ing. Informatica 1 ILP Instruction-level Parallelism
Outline Review: Basic Pipeline Scheduling and Loop Unrolling Multiple Issue: Superscalar, VLIW. CPE 631 Session 19 Exploiting ILP with SW Approaches
 Session xploiting ILP with SW Approaches lectrical and Computer ngineering University of Alabama in Huntsville Outline Review: Basic Pipeline Scheduling and Loop Unrolling Multiple Issue: Superscalar,
Session xploiting ILP with SW Approaches lectrical and Computer ngineering University of Alabama in Huntsville Outline Review: Basic Pipeline Scheduling and Loop Unrolling Multiple Issue: Superscalar,
ECE 486/586. Computer Architecture. Lecture # 12
 ECE 486/586 Computer Architecture Lecture # 12 Spring 2015 Portland State University Lecture Topics Pipelining Control Hazards Delayed branch Branch stall impact Implementing the pipeline Detecting hazards
ECE 486/586 Computer Architecture Lecture # 12 Spring 2015 Portland State University Lecture Topics Pipelining Control Hazards Delayed branch Branch stall impact Implementing the pipeline Detecting hazards
Control Hazards - branching causes problems since the pipeline can be filled with the wrong instructions.
 Control Hazards - branching causes problems since the pipeline can be filled with the wrong instructions Stage Instruction Fetch Instruction Decode Execution / Effective addr Memory access Write-back Abbreviation
Control Hazards - branching causes problems since the pipeline can be filled with the wrong instructions Stage Instruction Fetch Instruction Decode Execution / Effective addr Memory access Write-back Abbreviation
Four Steps of Speculative Tomasulo cycle 0
 HW support for More ILP Hardware Speculative Execution Speculation: allow an instruction to issue that is dependent on branch, without any consequences (including exceptions) if branch is predicted incorrectly
HW support for More ILP Hardware Speculative Execution Speculation: allow an instruction to issue that is dependent on branch, without any consequences (including exceptions) if branch is predicted incorrectly
EITF20: Computer Architecture Part3.2.1: Pipeline - 3
 EITF20: Computer Architecture Part3.2.1: Pipeline - 3 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Dynamic scheduling - Tomasulo Superscalar, VLIW Speculation ILP limitations What we have done
EITF20: Computer Architecture Part3.2.1: Pipeline - 3 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Dynamic scheduling - Tomasulo Superscalar, VLIW Speculation ILP limitations What we have done
E0-243: Computer Architecture
 E0-243: Computer Architecture L1 ILP Processors RG:E0243:L1-ILP Processors 1 ILP Architectures Superscalar Architecture VLIW Architecture EPIC, Subword Parallelism, RG:E0243:L1-ILP Processors 2 Motivation
E0-243: Computer Architecture L1 ILP Processors RG:E0243:L1-ILP Processors 1 ILP Architectures Superscalar Architecture VLIW Architecture EPIC, Subword Parallelism, RG:E0243:L1-ILP Processors 2 Motivation
Advanced Computer Architecture
 Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
ADVANCED COMPUTER ARCHITECTURES: Prof. C. SILVANO Written exam 11 July 2011
 ADVANCED COMPUTER ARCHITECTURES: 088949 Prof. C. SILVANO Written exam 11 July 2011 SURNAME NAME ID EMAIL SIGNATURE EX1 (3) EX2 (3) EX3 (3) EX4 (5) EX5 (5) EX6 (4) EX7 (5) EX8 (3+2) TOTAL (33) EXERCISE
ADVANCED COMPUTER ARCHITECTURES: 088949 Prof. C. SILVANO Written exam 11 July 2011 SURNAME NAME ID EMAIL SIGNATURE EX1 (3) EX2 (3) EX3 (3) EX4 (5) EX5 (5) EX6 (4) EX7 (5) EX8 (3+2) TOTAL (33) EXERCISE
5008: Computer Architecture
 5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
Predict Not Taken. Revisiting Branch Hazard Solutions. Filling the delay slot (e.g., in the compiler) Delayed Branch
 Delayed Branch") branch taken Revisiting Branch Hazard Solutions Stall Predict Not Taken Predict Taken Branch Delay Slot Branch I+1 I+2 I+3 Predict Not Taken branch not taken Branch I+1 IF (bubble) (bubble) (bubble) (bubble)
branch taken Revisiting Branch Hazard Solutions Stall Predict Not Taken Predict Taken Branch Delay Slot Branch I+1 I+2 I+3 Predict Not Taken branch not taken Branch I+1 IF (bubble) (bubble) (bubble) (bubble)
Instr. execution impl. view
 Pipelining Sangyeun Cho Computer Science Department Instr. execution impl. view Single (long) cycle implementation Multi-cycle implementation Pipelined implementation Processing an instruction Fetch instruction
Pipelining Sangyeun Cho Computer Science Department Instr. execution impl. view Single (long) cycle implementation Multi-cycle implementation Pipelined implementation Processing an instruction Fetch instruction
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1
 CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Minimizing Data hazard Stalls by Forwarding Data Hazard Classification Data Hazards Present in Current MIPS Pipeline
 Instruction Pipelining Review: MIPS In-Order Single-Issue Integer Pipeline Performance of Pipelines with Stalls Pipeline Hazards Structural hazards Data hazards Minimizing Data hazard Stalls by Forwarding
Instruction Pipelining Review: MIPS In-Order Single-Issue Integer Pipeline Performance of Pipelines with Stalls Pipeline Hazards Structural hazards Data hazards Minimizing Data hazard Stalls by Forwarding
Handout 2 ILP: Part B
 Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Instruction Level Parallelism. ILP, Loop level Parallelism Dependences, Hazards Speculation, Branch prediction
 Instruction Level Parallelism ILP, Loop level Parallelism Dependences, Hazards Speculation, Branch prediction Basic Block A straight line code sequence with no branches in except to the entry and no branches
Instruction Level Parallelism ILP, Loop level Parallelism Dependences, Hazards Speculation, Branch prediction Basic Block A straight line code sequence with no branches in except to the entry and no branches
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Department of Computer and IT Engineering University of Kurdistan. Computer Architecture Pipelining. By: Dr. Alireza Abdollahpouri
 Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
Advanced Parallel Architecture Lessons 5 and 6. Annalisa Massini /2017
 Advanced Parallel Architecture Lessons 5 and 6 Annalisa Massini - Pipelining Hennessy, Patterson Computer architecture A quantitive approach Appendix C Sections C.1, C.2 Pipelining Pipelining is an implementation
Advanced Parallel Architecture Lessons 5 and 6 Annalisa Massini - Pipelining Hennessy, Patterson Computer architecture A quantitive approach Appendix C Sections C.1, C.2 Pipelining Pipelining is an implementation
ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5)
 Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5)") Instruction-Level Parallelism and its Exploitation: PART 1 ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5) Project and Case
Instruction-Level Parallelism and its Exploitation: PART 1 ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5) Project and Case
Pipeline Overview. Dr. Jiang Li. Adapted from the slides provided by the authors. Jiang Li, Ph.D. Department of Computer Science
 Pipeline Overview Dr. Jiang Li Adapted from the slides provided by the authors Outline MIPS An ISA for Pipelining 5 stage pipelining Structural and Data Hazards Forwarding Branch Schemes Exceptions and
Pipeline Overview Dr. Jiang Li Adapted from the slides provided by the authors Outline MIPS An ISA for Pipelining 5 stage pipelining Structural and Data Hazards Forwarding Branch Schemes Exceptions and
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
Pipelining. CSC Friday, November 6, 2015
 Pipelining CSC 211.01 Friday, November 6, 2015 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory register file ALU data memory register file Not
Pipelining CSC 211.01 Friday, November 6, 2015 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory register file ALU data memory register file Not
CIS 662: Midterm. 16 cycles, 6 stalls
 CIS 662: Midterm Name: Points: /100 First read all the questions carefully and note how many points each question carries and how difficult it is. You have 1 hour 15 minutes. Plan your time accordingly.
CIS 662: Midterm Name: Points: /100 First read all the questions carefully and note how many points each question carries and how difficult it is. You have 1 hour 15 minutes. Plan your time accordingly.
Instruction Pipelining Review
 Instruction Pipelining Review Instruction pipelining is CPU implementation technique where multiple operations on a number of instructions are overlapped. An instruction execution pipeline involves a number
Instruction Pipelining Review Instruction pipelining is CPU implementation technique where multiple operations on a number of instructions are overlapped. An instruction execution pipeline involves a number
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
EECC551 Exam Review 4 questions out of 6 questions
 EECC551 Exam Review 4 questions out of 6 questions (Must answer first 2 questions and 2 from remaining 4) Instruction Dependencies and graphs In-order Floating Point/Multicycle Pipelining (quiz 2) Improving
EECC551 Exam Review 4 questions out of 6 questions (Must answer first 2 questions and 2 from remaining 4) Instruction Dependencies and graphs In-order Floating Point/Multicycle Pipelining (quiz 2) Improving
Review: Pipelining. Key to pipelining: smooth flow Making all instructions the same length can increase performance!
 Review: Pipelining CS152 Computer Architecture and Engineering Lecture 15 Advanced pipelining/compiler Scheduling October 24, 2001 John Kubiatowicz (http.cs.berkeley.edu/~kubitron) lecture slides: http://www-inst.eecs.berkeley.edu/~cs152/
Review: Pipelining CS152 Computer Architecture and Engineering Lecture 15 Advanced pipelining/compiler Scheduling October 24, 2001 John Kubiatowicz (http.cs.berkeley.edu/~kubitron) lecture slides: http://www-inst.eecs.berkeley.edu/~cs152/
CS433 Homework 3 (Chapter 3)
") CS433 Homework 3 (Chapter 3) Assigned on 10/3/2017 Due in class on 10/17/2017 Instructions: 1. Please write your name and NetID clearly on the first page. 2. Refer to the course fact sheet for policies
CS433 Homework 3 (Chapter 3) Assigned on 10/3/2017 Due in class on 10/17/2017 Instructions: 1. Please write your name and NetID clearly on the first page. 2. Refer to the course fact sheet for policies
RECAP. B649 Parallel Architectures and Programming
 RECAP B649 Parallel Architectures and Programming RECAP 2 Recap ILP Exploiting ILP Dynamic scheduling Thread-level Parallelism Memory Hierarchy Other topics through student presentations Virtual Machines
RECAP B649 Parallel Architectures and Programming RECAP 2 Recap ILP Exploiting ILP Dynamic scheduling Thread-level Parallelism Memory Hierarchy Other topics through student presentations Virtual Machines
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.
 Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.") Instruction-Level Parallelism and its Exploitation: PART 2 Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.8)
Instruction-Level Parallelism and its Exploitation: PART 2 Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.8)
Pipeline issues. Pipeline hazard: RaW. Pipeline hazard: RaW. Calcolatori Elettronici e Sistemi Operativi. Hazards. Data hazard.
 Calcolatori Elettronici e Sistemi Operativi Pipeline issues Hazards Pipeline issues Data hazard Control hazard Structural hazard Pipeline hazard: RaW Pipeline hazard: RaW 5 6 7 8 9 5 6 7 8 9 : add R,R,R
Calcolatori Elettronici e Sistemi Operativi Pipeline issues Hazards Pipeline issues Data hazard Control hazard Structural hazard Pipeline hazard: RaW Pipeline hazard: RaW 5 6 7 8 9 5 6 7 8 9 : add R,R,R
ארכיטקטורת יחידת עיבוד מרכזי ת
 ארכיטקטורת יחידת עיבוד מרכזי ת (36113741) תשס"ג סמסטר א' July 2, 2008 Hugo Guterman (hugo@ee.bgu.ac.il) Arch. CPU L8 Cache Intr. 1/77 Memory Hierarchy Arch. CPU L8 Cache Intr. 2/77 Why hierarchy works
ארכיטקטורת יחידת עיבוד מרכזי ת (36113741) תשס"ג סמסטר א' July 2, 2008 Hugo Guterman (hugo@ee.bgu.ac.il) Arch. CPU L8 Cache Intr. 1/77 Memory Hierarchy Arch. CPU L8 Cache Intr. 2/77 Why hierarchy works
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
Reduction of Data Hazards Stalls with Dynamic Scheduling So far we have dealt with data hazards in instruction pipelines by:
 Reduction of Data Hazards Stalls with Dynamic Scheduling So far we have dealt with data hazards in instruction pipelines by: Result forwarding (register bypassing) to reduce or eliminate stalls needed
Reduction of Data Hazards Stalls with Dynamic Scheduling So far we have dealt with data hazards in instruction pipelines by: Result forwarding (register bypassing) to reduce or eliminate stalls needed
TDT 4260 TDT ILP Chap 2, App. C
 TDT 4260 ILP Chap 2, App. C Intro Ian Bratt (ianbra@idi.ntnu.no) ntnu no) Instruction level parallelism (ILP) A program is sequence of instructions typically written to be executed one after the other
TDT 4260 ILP Chap 2, App. C Intro Ian Bratt (ianbra@idi.ntnu.no) ntnu no) Instruction level parallelism (ILP) A program is sequence of instructions typically written to be executed one after the other
Ti Parallel Computing PIPELINING. Michał Roziecki, Tomáš Cipr
 Ti5317000 Parallel Computing PIPELINING Michał Roziecki, Tomáš Cipr 2005-2006 Introduction to pipelining What is this What is pipelining? Pipelining is an implementation technique in which multiple instructions
Ti5317000 Parallel Computing PIPELINING Michał Roziecki, Tomáš Cipr 2005-2006 Introduction to pipelining What is this What is pipelining? Pipelining is an implementation technique in which multiple instructions
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Chapter 3 (CONT II) Instructor: Josep Torrellas CS433. Copyright J. Torrellas 1999,2001,2002,2007,
 Instructor: Josep Torrellas CS433. Copyright J. Torrellas 1999,2001,2002,2007,") Chapter 3 (CONT II) Instructor: Josep Torrellas CS433 Copyright J. Torrellas 1999,2001,2002,2007, 2013 1 Hardware-Based Speculation (Section 3.6) In multiple issue processors, stalls due to branches would
Chapter 3 (CONT II) Instructor: Josep Torrellas CS433 Copyright J. Torrellas 1999,2001,2002,2007, 2013 1 Hardware-Based Speculation (Section 3.6) In multiple issue processors, stalls due to branches would
Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome
 Pipeline Thoai Nam Outline Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome Reference: Computer Architecture: A Quantitative Approach, John L Hennessy
Pipeline Thoai Nam Outline Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome Reference: Computer Architecture: A Quantitative Approach, John L Hennessy
CS152 Computer Architecture and Engineering Lecture 15
 CS152 Computer Architecture and Engineering Lecture 15 Advanced pipelining/compiler Scheduling Dynamic Scheduling I March 13, 2001 John Kubiatowicz (http.cs.berkeley.edu/~kubitron) lecture slides: http://www-inst.eecs.berkeley.edu/~cs152/
CS152 Computer Architecture and Engineering Lecture 15 Advanced pipelining/compiler Scheduling Dynamic Scheduling I March 13, 2001 John Kubiatowicz (http.cs.berkeley.edu/~kubitron) lecture slides: http://www-inst.eecs.berkeley.edu/~cs152/
Super Scalar. Kalyan Basu March 21,
 Super Scalar Kalyan Basu basu@cse.uta.edu March 21, 2007 1 Super scalar Pipelines A pipeline that can complete more than 1 instruction per cycle is called a super scalar pipeline. We know how to build
Super Scalar Kalyan Basu basu@cse.uta.edu March 21, 2007 1 Super scalar Pipelines A pipeline that can complete more than 1 instruction per cycle is called a super scalar pipeline. We know how to build
The Processor: Instruction-Level Parallelism
 The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
CS 252 Graduate Computer Architecture. Lecture 4: Instruction-Level Parallelism
 CS 252 Graduate Computer Architecture Lecture 4: Instruction-Level Parallelism Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://wwweecsberkeleyedu/~krste
CS 252 Graduate Computer Architecture Lecture 4: Instruction-Level Parallelism Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://wwweecsberkeleyedu/~krste
CMSC411 Fall 2013 Midterm 2 Solutions
 CMSC411 Fall 2013 Midterm 2 Solutions 1. (12 pts) Memory hierarchy a. (6 pts) Suppose we have a virtual memory of size 64 GB, or 2 36 bytes, where pages are 16 KB (2 14 bytes) each, and the machine has
CMSC411 Fall 2013 Midterm 2 Solutions 1. (12 pts) Memory hierarchy a. (6 pts) Suppose we have a virtual memory of size 64 GB, or 2 36 bytes, where pages are 16 KB (2 14 bytes) each, and the machine has
Graduate Computer Architecture. Chapter 3. Instruction Level Parallelism and Its Dynamic Exploitation
 Graduate Computer Architecture Chapter 3 Instruction Level Parallelism and Its Dynamic Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques Scoreboarding (Appendix A.8) Tomasulo
Graduate Computer Architecture Chapter 3 Instruction Level Parallelism and Its Dynamic Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques Scoreboarding (Appendix A.8) Tomasulo
COSC 6385 Computer Architecture - Pipelining
 COSC 6385 Computer Architecture - Pipelining Fall 2006 Some of the slides are based on a lecture by David Culler, Instruction Set Architecture Relevant features for distinguishing ISA s Internal storage
COSC 6385 Computer Architecture - Pipelining Fall 2006 Some of the slides are based on a lecture by David Culler, Instruction Set Architecture Relevant features for distinguishing ISA s Internal storage
Donn Morrison Department of Computer Science. TDT4255 ILP and speculation
 TDT4255 Lecture 9: ILP and speculation Donn Morrison Department of Computer Science 2 Outline Textbook: Computer Architecture: A Quantitative Approach, 4th ed Section 2.6: Speculation Section 2.7: Multiple
TDT4255 Lecture 9: ILP and speculation Donn Morrison Department of Computer Science 2 Outline Textbook: Computer Architecture: A Quantitative Approach, 4th ed Section 2.6: Speculation Section 2.7: Multiple
CPE 631 Lecture 11: Instruction Level Parallelism and Its Dynamic Exploitation
 Lecture 11: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Instruction
Lecture 11: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Instruction
CPE 631 Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation
 Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Tomasulo
Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Tomasulo
EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems)
") EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems) Chentao Wu 吴晨涛 Associate Professor Dept. of Computer Science and Engineering Shanghai Jiao Tong University SEIEE Building
EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems) Chentao Wu 吴晨涛 Associate Professor Dept. of Computer Science and Engineering Shanghai Jiao Tong University SEIEE Building
CS2100 Computer Organisation Tutorial #10: Pipelining Answers to Selected Questions
 CS2100 Computer Organisation Tutorial #10: Pipelining Answers to Selected Questions Tutorial Questions 2. [AY2014/5 Semester 2 Exam] Refer to the following MIPS program: # register $s0 contains a 32-bit
CS2100 Computer Organisation Tutorial #10: Pipelining Answers to Selected Questions Tutorial Questions 2. [AY2014/5 Semester 2 Exam] Refer to the following MIPS program: # register $s0 contains a 32-bit
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Lecture 2: Processor and Pipelining 1
 The Simple BIG Picture! Chapter 3 Additional Slides The Processor and Pipelining CENG 6332 2 Datapath vs Control Datapath signals Control Points Controller Datapath: Storage, FU, interconnect sufficient
The Simple BIG Picture! Chapter 3 Additional Slides The Processor and Pipelining CENG 6332 2 Datapath vs Control Datapath signals Control Points Controller Datapath: Storage, FU, interconnect sufficient
Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining
 Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining Single-Cycle Design Problems Assuming fixed-period clock every instruction datapath uses one
Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining Single-Cycle Design Problems Assuming fixed-period clock every instruction datapath uses one
Computer Architecture. Lecture 6.1: Fundamentals of
 CS3350B Computer Architecture Winter 2015 Lecture 6.1: Fundamentals of Instructional Level Parallelism Marc Moreno Maza www.csd.uwo.ca/courses/cs3350b [Adapted from lectures on Computer Organization and
CS3350B Computer Architecture Winter 2015 Lecture 6.1: Fundamentals of Instructional Level Parallelism Marc Moreno Maza www.csd.uwo.ca/courses/cs3350b [Adapted from lectures on Computer Organization and
Dynamic Scheduling. CSE471 Susan Eggers 1
 Dynamic Scheduling Why go out of style? expensive hardware for the time (actually, still is, relatively) register files grew so less register pressure early RISCs had lower CPIs Why come back? higher chip
Dynamic Scheduling Why go out of style? expensive hardware for the time (actually, still is, relatively) register files grew so less register pressure early RISCs had lower CPIs Why come back? higher chip
Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome
 Thoai Nam Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome Reference: Computer Architecture: A Quantitative Approach, John L Hennessy & David a Patterson,
Thoai Nam Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome Reference: Computer Architecture: A Quantitative Approach, John L Hennessy & David a Patterson,
Processor (IV) - advanced ILP. Hwansoo Han
 - advanced ILP. Hwansoo Han") Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
Pipelining. Maurizio Palesi
 * Pipelining * Adapted from David A. Patterson s CS252 lecture slides, http://www.cs.berkeley/~pattrsn/252s98/index.html Copyright 1998 UCB 1 References John L. Hennessy and David A. Patterson, Computer
* Pipelining * Adapted from David A. Patterson s CS252 lecture slides, http://www.cs.berkeley/~pattrsn/252s98/index.html Copyright 1998 UCB 1 References John L. Hennessy and David A. Patterson, Computer
Pipelining: Hazards Ver. Jan 14, 2014
 POLITECNICO DI MILANO Parallelism in wonderland: are you ready to see how deep the rabbit hole goes? Pipelining: Hazards Ver. Jan 14, 2014 Marco D. Santambrogio: marco.santambrogio@polimi.it Simone Campanoni:
POLITECNICO DI MILANO Parallelism in wonderland: are you ready to see how deep the rabbit hole goes? Pipelining: Hazards Ver. Jan 14, 2014 Marco D. Santambrogio: marco.santambrogio@polimi.it Simone Campanoni:
Determined by ISA and compiler. We will examine two MIPS implementations. A simplified version A more realistic pipelined version
 MIPS Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
MIPS Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Review: Summary of Pipelining Basics
 Review: ummary of Pipelining asics C152 Computer Architecture and Engineering Lecture 14 Pipelining Control Continued Introduction to Advanced Pipelining October 18, 1999 John Kubiatowicz (http.cs.berkeley.edu/~kubitron)
Review: ummary of Pipelining asics C152 Computer Architecture and Engineering Lecture 14 Pipelining Control Continued Introduction to Advanced Pipelining October 18, 1999 John Kubiatowicz (http.cs.berkeley.edu/~kubitron)
MIPS ISA AND PIPELINING OVERVIEW Appendix A and C
 1 MIPS ISA AND PIPELINING OVERVIEW Appendix A and C OUTLINE Review of MIPS ISA Review on Pipelining 2 READING ASSIGNMENT ReadAppendixA ReadAppendixC 3 THEMIPS ISA (A.9) First MIPS in 1985 General-purpose
1 MIPS ISA AND PIPELINING OVERVIEW Appendix A and C OUTLINE Review of MIPS ISA Review on Pipelining 2 READING ASSIGNMENT ReadAppendixA ReadAppendixC 3 THEMIPS ISA (A.9) First MIPS in 1985 General-purpose
Computer Architecture
 Lecture 3: Pipelining Iakovos Mavroidis Computer Science Department University of Crete 1 Previous Lecture Measurements and metrics : Performance, Cost, Dependability, Power Guidelines and principles in
Lecture 3: Pipelining Iakovos Mavroidis Computer Science Department University of Crete 1 Previous Lecture Measurements and metrics : Performance, Cost, Dependability, Power Guidelines and principles in
CS152 Computer Architecture and Engineering. Complex Pipelines
 CS152 Computer Architecture and Engineering Complex Pipelines Assigned March 6 Problem Set #3 Due March 20 http://inst.eecs.berkeley.edu/~cs152/sp12 The problem sets are intended to help you learn the
CS152 Computer Architecture and Engineering Complex Pipelines Assigned March 6 Problem Set #3 Due March 20 http://inst.eecs.berkeley.edu/~cs152/sp12 The problem sets are intended to help you learn the
Lecture 8 Dynamic Branch Prediction, Superscalar and VLIW. Computer Architectures S
 Lecture 8 Dynamic Branch Prediction, Superscalar and VLIW Computer Architectures 521480S Dynamic Branch Prediction Performance = ƒ(accuracy, cost of misprediction) Branch History Table (BHT) is simplest
Lecture 8 Dynamic Branch Prediction, Superscalar and VLIW Computer Architectures 521480S Dynamic Branch Prediction Performance = ƒ(accuracy, cost of misprediction) Branch History Table (BHT) is simplest
Chapter 4 The Processor (Part 4)
") Department of Electr rical Eng ineering, Chapter 4 The Processor (Part 4) 王振傑 (Chen-Chieh Wang) ccwang@mail.ee.ncku.edu.tw ncku edu Depar rtment of Electr rical Engineering, Feng-Chia Unive ersity Outline
Department of Electr rical Eng ineering, Chapter 4 The Processor (Part 4) 王振傑 (Chen-Chieh Wang) ccwang@mail.ee.ncku.edu.tw ncku edu Depar rtment of Electr rical Engineering, Feng-Chia Unive ersity Outline
CSE502 Lecture 15 - Tue 3Nov09 Review: MidTerm Thu 5Nov09 - Outline of Major Topics
 CSE502 Lecture 15 - Tue 3Nov09 Review: MidTerm Thu 5Nov09 - Outline of Major Topics Computing system: performance, speedup, performance/cost Origins and benefits of scalar instruction pipelines and caches
CSE502 Lecture 15 - Tue 3Nov09 Review: MidTerm Thu 5Nov09 - Outline of Major Topics Computing system: performance, speedup, performance/cost Origins and benefits of scalar instruction pipelines and caches
Page 1. Pipelining: Its Natural! Chapter 3. Pipelining. Pipelined Laundry Start work ASAP. Sequential Laundry A B C D. 6 PM Midnight
 Pipelining: Its Natural! Chapter 3 Pipelining Laundry Example Ann, Brian, Cathy, Dave each have one load of clothes to wash, dry, and fold Washer takes 30 minutes A B C D Dryer takes 40 minutes Folder
Pipelining: Its Natural! Chapter 3 Pipelining Laundry Example Ann, Brian, Cathy, Dave each have one load of clothes to wash, dry, and fold Washer takes 30 minutes A B C D Dryer takes 40 minutes Folder
Lecture 9: Case Study MIPS R4000 and Introduction to Advanced Pipelining Professor Randy H. Katz Computer Science 252 Spring 1996
 Lecture 9: Case Study MIPS R4000 and Introduction to Advanced Pipelining Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.SP96 1 Review: Evaluating Branch Alternatives Two part solution: Determine
Lecture 9: Case Study MIPS R4000 and Introduction to Advanced Pipelining Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.SP96 1 Review: Evaluating Branch Alternatives Two part solution: Determine
Week 11: Assignment Solutions
 Week 11: Assignment Solutions 1. Consider an instruction pipeline with four stages with the stage delays 5 nsec, 6 nsec, 11 nsec, and 8 nsec respectively. The delay of an inter-stage register stage of
Week 11: Assignment Solutions 1. Consider an instruction pipeline with four stages with the stage delays 5 nsec, 6 nsec, 11 nsec, and 8 nsec respectively. The delay of an inter-stage register stage of
CPI < 1? How? What if dynamic branch prediction is wrong? Multiple issue processors: Speculative Tomasulo Processor
 1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
EECC551 - Shaaban. 1 GHz? to???? GHz CPI > (?)
") Evolution of Processor Performance So far we examined static & dynamic techniques to improve the performance of single-issue (scalar) pipelined CPU designs including: static & dynamic scheduling, static
Evolution of Processor Performance So far we examined static & dynamic techniques to improve the performance of single-issue (scalar) pipelined CPU designs including: static & dynamic scheduling, static